先日、AWSで稼動しているEC2がダウンしたとお伝えしましたが、その続報です
関連記事:AWSで稼動させているEC2で障害発生 初心者の障害対応日記
今回の障害では、EC2の再起動などで復旧しなかった為、定期(毎日)スナップショットを取得しているので取得したスナップショットからAMI作成→インスタンスとして起動し復旧させました。
当時の状況を問題のあったインスタンスモニター履歴から考察してみました。
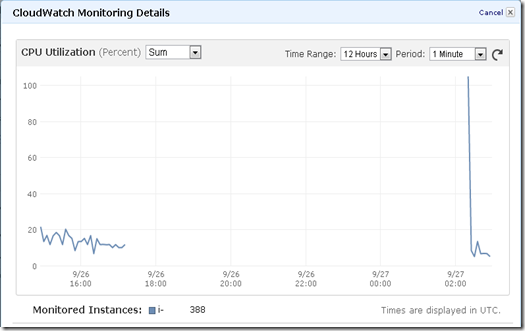
まずは、CPUですが時刻がUTC表記なので日本時間だと+9時間になります
グラフの9/26 17:00(UCT)頃なので日本時間では9/27AM2:00 このタイミングでCPUのグラフは途切れている
9/27 02:00(日本時間同日AM11:00)頃にCPUのグラフが再び跳ね上がります。このタイミングはインスタンスをSTOP→STARTした時間です
簡単な時系列(日本時間)を
AM2:00 ALARM: “-i-XXX9a388-Status-Check-Failed-Any” in APAC – Tokyoメール受信
AM6:00 httpdダウンのメール受信
AM11:00 インスタンスをSTOP→STARTさせました。
しかし、気になるのはAM2:00~6:00間のhttpdアクセスがどのようになっていたか?
私は無料のhttpd監視サービスを利用させていただいているシーマンのサーバー管理【無料】![]()
シーマンのデータだとAM2:00~6:00間はhttpdがダウンしていないとログに残っているがAWS側のコンソールで確認するとNetworkOutのグラフがCPUと同じタイミングで0になっている。
それぞれのログデータから
AWSはグラフに記録がない時点で障害と判断されている
シーマンはhttpdのレスポンスがあればOKとしている(200番かぁな?) 実際にはAM2:00~6:00間Webサイトをブラウザで確認していないので断言できませんがレスポンスはあったのかもしれない
内部 外部それぞれからの監視の必要性を再認識した一件だった 内部だけだとWebサイト(http)の表示は確認出来ない外部だけだとサーバーステータスの確認が出来ない
だから、AWSのcloudwatchとzabbixなどの監視ツールを組み合わせて運用を行うべきである
でも、早期復旧で良かった。
